Comment (ne pas) déployer une collecte Fluentd pour Docker
Docker et les journaux
Nous sommes en 2019 et l'on raffole de Docker. En particulier chez TeDomum, nous l'employons pour rationaliser nos travaux de déploiement et de configuration, pour faciliter le partage. Par exemple, l'ensemble de nos services, y compris les services d'infrastructure (sauvegardes, journalisation, statistiques, etc.) est déployé sous forme d'images Docker disponibles à tous et de projets Compose accessibles publiquement, ce qui assure que créer un hébergeur identique est l'affaire de quelques heures, et qu'on bénéficie de facto des mises à jour.
Les écoles varient, mais l'un des patterns usuels de gestion des journaux sous Docker consiste à employer exclusivement la sortie d'erreur et la sortie standard, puis confier à Docker le routage des messages. Cette approche est critiquable par beaucoup d'aspects, surtout son manque de souplesse, mais compense en simplicité et fait presque aujourd'hui l'unanimité. Elle a cela aussi d'avantageux que les choses fonctionnent bien, sans trop de complexité initiale, par exemple pour afficher les journaux du service app d'un projet Compose :
docker-compose logs --tail=100 app
Centraliser les journaux
Lorsqu'on commence à gérer des dizaines de projets Compose sur plusieurs serveurs, même plus généralement quand on multiplie les équipements et les services, il est de bon goût de centraliser rapidement les journaux. Cela permet non seulement de faciliter la détection de défaut avec des jeux d'alertes, mais c'est aussi bénéfique pour la gestion de la vie privée et des libertés : un point unique où les journaux peuvent être systématiquement nettoyés de leurs adresses IP, logins, autres informations personnelles ; un point unique où la rétention peut être limitée conformément à la jurisprudence européenne.
Plusieurs outils et standards pour ça : – syslog, historique mais très robuste, supporte chiffrement et signature des messages ; – Elastic, en appelant directement les endpoints d'un ElasticSearch pour y injecter des objets formattés JSON ; – Splunk, propriétaire et assimilable à une API HTTP ; – GELF, transporté en TCP, UDP ou HTTP, formalisé par Graylog et spécialisé pour le transport de journaux.
Historiquement, TeDomum utilisait Graylog pour la gestion de ses journaux, et nous avions donc favorisé GELF pour les transporter directement depuis le démon Docker. La configuration est simple (extrait de notre daemon.json de configuration Docker :
{
"log-driver": "gelf",
"log-opts": {"gelf-address":"udp://logs.server.hostname:12201"}
}
C'est une architecture simplissime, qu'on recommande vivement à quiconque gère une petite infrastructure à base de Docker. Attention toutefois à ce que les communications soient bien protégées (réseau privé) entre les hôtes et le serveur de journaux, de sorte que les traces ne soient pas interceptées.
Ses principaux défauts :
- la consommation de stockage (qu'on se le dise, un index Graylog doublé de son ElasticSearch pour la recheche, cela consomme plus de 5 fois le volume des journaux ingérés ; TeDomum le payait de 50Go assignés au journaux pour une semaine de rétention environ) ;
- la consommation en RAM (de même, pour un moteur applicatif sur OpenJDK accompagné d'un ElasticSearch, compter au minimum 3Go) ;
- on ne collecte que Docker en l'état.
Fluentd pour plus de souplesse
S'agissant de collecter les journaux système, nous employons actuellement journald sur tous nos hôtes car déployé nativement sous notre distribution, Debian Buster.
Malheureusement, journald n'implémente pas de transmission de journaux au format GELF, un agent intermédiaire est donc nécessaire. Les principales technologies sont à ce titre :
- rsyslog, originalement orienté syslog mais aujourd'hui très généraliste pour router des messages, sa configuration est malheureusement complexe ;
- Logstash, très accessible et composant essentiel de ELK, gourmand en ressources toutefois ;
- Fluentd et son petit frère FluentBit bien plus légers et toujours accessibles.
Par principe conservateur, nous avons opté pour Fluentd en attendant un support plus large de la communauté de FluentBit. Déjà franchement léger (compter quelques dizaines de Mo, au pire 200Mo pour une instance), l'agent est capable de traiter de nombreux types d'entrée et de les router vers la même variété de destinations (ElasticSearch, Mongo, fichiers plats, tout y passe, et les modules existent pour étendre). En prime, Docker supporte officiellement le format d'entrée natif, et il existe un module natif pour journald, impeccable !
Nous avons donc imaginé une infrastructure simple, reposant sur Fluentd déployé localement sur chaque hôte ; il peut même y effectuer des pré-nettoyages et pré-traitements. Chaque Fluentd rappatrie ses journaux collectés de Docker et de journald vers un serveur central assurant le processing et le stockage.
Loki, petit nouveau très complet
TeDomum emploie déjà Prometheus pour collecter l'ensemble de ses métriques. Même notre robot de supervision Anna publie des métriques Prometheus sur la supervision des services (combien de temps met un message pour être délivré de chez nous à tel ou tel fournisseur de mails, etc.) Nous consultons ces métriques collectées via Grafana, leader libre de la visualisation de métriques. Grafana est très complet et nous sert dans de nombreux cas d'investigation ; il était auparavant employé aux côtés de Graylog pour la consultation.
Il y a quelques mois, Grafana annonçait la sortie de Loki, une solution de centralisation de journaux façon Prometheus : légère, reposant sur des principes simples mais performants, et surtout complètement intégrée à Grafana. Il faut l'avouer : pouvoir afficher côte à côte les statistiques d'accès à un service et les journaux de ce service, difficile de refuser.
Nous avons donc expérimenté avec Loki, et avons abouti à une configuration plutôt simple mais solide. Nous pouvons aujourd'hui en une seule requête : {"app": "mastodon"} ou {"service": "db"} cibler les statistiques et les journaux d'un type de service, d'une application entière et les affichers sur une même fenêtre.

Nous avons donc orienté notre configuration Fluentd pour employer Loki en moteur de stockage, ce qui s'avère plutôt aisé avec un plugin développé officiellement par Grafana.
Un déploiement sans encombre
Après une phase de laboratoire, quelques jours d'expérimentation sur une fraction de notre production, la décision était prise jeudi 9 de profiter d'un redémarrage – mise à jour oblige – pour basculer le premier de nos serveurs entièrement sous Fluentd et Loki côté journalisation.
Pour l'occasion, nous avons déployé Fluentd dans un conteneur local, qui écoute sur un socket unix :
<source>
@type unix
@id in_docker
@label docker
path /var/log/fluentd.socket
</source>
Et Docker qui pointe ses journaux vers le socket :
{
"log-driver": "fluentd",
"log-opts": {
"fluentd-address": "unix:///var/log/fluentd.socket",
"fluentd-async-connect": "true",
"fluentd-retry-wait": "30s"
}
}
Le choix de la connexion asynchrone est nécessaire, puisque Fluentd étant lui-même conteneurisé, Docker ne parvient à lancer aucun conteneur tant que le service n'est pas disponible sur le socket.
Après un premier déploiement réussi, la même configuration est appliquée partout. Rapidement l'ensemble des journaux remonte vers Loki : un bonheur.
Et les ennuis commencent...
C'est jeudi soir que les premiers ennuis se font sentir. Le symptôme est simple, plus aucun service n'est accessible sur l'un de nos serveurs : joke. Naturellement on fait le lien avec le nouveau déploiement, mais comme plusieurs mises à jour ont également été appliquées, rien n'est évident.
Un diagnostic rapide montre que les services eux-mêmes ne sont pas en défaut, mais que le frontal traefik ne répond plus aux requêtes (il n'accepte même plus de connexion TCP). Qu'à cela ne tienne, avant d'investiguer, on le redémarre pour rétablir le service :
docker-compose restart traefik
Restarting front_traefik_1 ...
ERROR: for front_traefik_1 UnixHTTPConnectionPool(host='localhost', port=None): Read timed out. (read timeout=70)
ERROR: An HTTP request took too long to complete. Retry with --verbose to obtain debug information.
If you encounter this issue regularly because of slow network conditions, consider setting COMPOSE_HTTP_TIMEOUT to a higher value (current value: 60).
Le stress grimpe un petit peu, et pour rétablir les choses assurément, on redémarre le démon Docker et l'ensemble des services. Tout rentre dans l'ordre, un « glitch » passager tente-t-on de se rassurer. Le diagnostic matériel ne donne par ailleurs aucune information, rien non plus dans les journaux système ou noyau.
Un « glitch » passager
S'il y a une chose acquise depuis qu'on administre un hébergeur, c'est qu'un « glitch » passager n'existe pas. On s'en rassure, mais il y a toujours une cause derrière chaque défaut, et souvent elle revient à la charge.
Vendredi, ce n'est pas un mais trois plantages du même serveur, joke, auxquels nous avons fait face. Très difficile à vivre pour un hébergeur habitué à quelques défauts mais rarement de panne générale. Aussi, en fin d'après midi, pas enclins à passer la nuit à surveiller les compteurs, on décide de rappatrier sur une autre machine nos services les plus délicats.
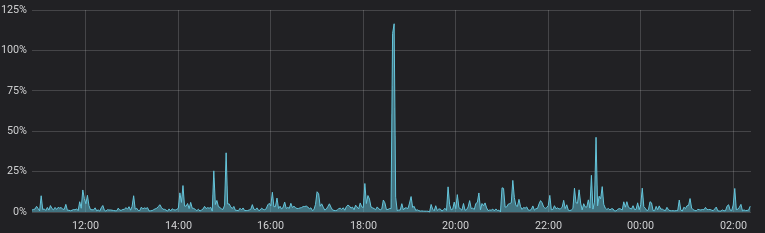
En parallèle, on investigue rapidement. Le défaut semble lié à un gros volume de journaux comme en témoigne les statistiques (en octets par seconde reçus par Loki). On distingue parfaitement les horaires des trois dénis de service :

Ces statistiques sont effectivement corrélées avec l'émission réseau par le conteneur Fluentd sur joke :

Malheureusement, il ne semble pas qu'un seul de ces journaux reçus apparaisse dans Loki ; on ne sait donc pas qui les génère ni pourquoi ils empêchent Fluentd ou traefik de fonctionner. Les statistiques CPU laissent tout de même entendre que PeerTube est particulièrement actif au moins sur l'un des défauts :
On décide de conserver PeerTube sur joke pour ne pas risquer d'impacter les autres hôtes et on projette d'investiguer pendant le week-end.
Vers un début de solution
A notre surprise samedi, c'est l'hôte où l'on a justement migré les services qui fait défaut. Une fois, puis deux. On s'apprête à conclure que c'est l'un des services migrés qui déclenche le bug lorsque joke tombe à nouveau : nos certitudes s'effondrent.
Toutes nos hypothèses à l'eau, on profite du défaut de joke sans service critique pour investiguer plus tranquillement. D'abord, on confirme le volume de journaux importants à chaque plantage ; ils n'apparaissent toujours pas dans Loki pour une raison qu'on ignore – un défaut de parsing suppose-t-on – aussi on active une copie locale dans un fichier.
<match **>
@type copy
<store>
@type loki
...
</store>
<store>
@type file
path /logs/fluentd.log
</store>
</match>
Egalement, en tentant d'isoler le défaut de Docker on constate que seul le conteneur traefik est impacté. Le reste fonctionne impeccablement, et aucun autre timeout n'est constaté. Dernier pas en avant (et pas des moindres) dans notre réflexion, redémarrer le conteneur Fluentd résoud le problème.
Non seulement cela nous offre une solution meilleur marché que redémarrer l'ensemble des services si le défaut se reproduit, mais cela confirme une chose : le lien clair avec Fluentd. Notre hypothèse à ce stade : quelque chose déclenche le traitement d'un gros volume de journaux dans Fluentd ; puis soit la forme soit le seul volume de ces journaux rend Fluend inopérant, y compris sur son socket (ce qui est normalement impossible grâce au mécanismes internes de buffer de Fluentd) ; Docker, ne pouvant écrire sur le socket de logs, refuse de traiter la sortie standard et la sortie d'erreur des conteneurs ; traefik est bloquant dans son écriture de journaux et se retrouve donc inopérant.
On laisse l'infrastructure en l'état en espérérant que les traces générées par un plantage prochain offriront quelques éclairages.
Le déni de service auto-infligé
Les traces n'ont pas tardé à tomber ce dimanche, nous n'avons pu les analyser que ce matin.
-rw-r--r-- 1 root root 244M May 12 13:01 fluent.log.20190512_0.log
-rw-r--r-- 1 root root 244M May 12 21:19 fluent.log.20190512_1.log
-rw-r--r-- 1 root root 244M May 12 22:17 fluent.log.20190512_2.log
-rw-r--r-- 1 root root 244M May 12 22:17 fluent.log.20190512_3.log
-rw-r--r-- 1 root root 244M May 12 22:17 fluent.log.20190512_4.log
-rw-r--r-- 1 root root 244M May 12 22:17 fluent.log.20190512_5.log
-rw-r--r-- 1 root root 244M May 12 22:18 fluent.log.20190512_6.log
-rw-r--r-- 1 root root 244M May 12 22:18 fluent.log.20190512_7.log
-rw-r--r-- 1 root root 244M May 12 22:18 fluent.log.20190512_8.log
-rw-r--r-- 1 root root 244M May 12 22:18 fluent.log.20190512_9.log
-rw-r--r-- 1 root root 212M May 13 02:46 fluent.log.20190512_10.log
-rw-r--r-- 1 root root 244M May 13 09:36 fluent.log.20190513_0.log
-rw-r--r-- 1 root root 244M May 13 09:36 fluent.log.20190513_1.log
-rw-r--r-- 1 root root 244M May 13 09:36 fluent.log.20190513_2.log
-rw-r--r-- 1 root root 244M May 13 09:37 fluent.log.20190513_3.log
-rw-r--r-- 1 root root 244M May 13 09:37 fluent.log.20190513_4.log
-rw-r--r-- 1 root root 244M May 13 09:37 fluent.log.20190513_5.log
-rw-r--r-- 1 root root 244M May 13 09:37 fluent.log.20190513_6.log
-rw-r--r-- 1 root root 244M May 13 09:37 fluent.log.20190513_7.log
-rw-r--r-- 1 root root 244M May 13 09:37 fluent.log.20190513_8.log
À 22h18 dimanche, puis à 9h37 ce matin, les horaires des derniers sursauts du serveur correspondent parfaitement à une flanquée de journaux écrits par Fluentd, comme nous l'attendions ! Pour ne pas tomber dans le défaut de parsing on les analyse avec des moyens simples : grep, awk et sort font l'affaire.
D'abord on confirme que PeerTube est à l'origine du plantage dans chacun des cas. Clin d'œil à l'ami virtualab qui a dû faire la publicité de son blog tout récemment, et quelques visiteurs parcourent ses pages où une vidéo PeerTube est intégrée, le client PeerTube générant beaucoup de requêtes pour charger la vidéo par morceaux. Il n'empêche que ces quelques 1000 requêtes par seconde consomment un petit peu de CPU sur les frontaux et PeerTube lui-même, mais ne devraient certainement pas inquiéter Fluentd, par ailleurs habitué à traiter des millions de lignes de journaux par seconde.
On se concentre donc sur les traces de Fluentd lui-même et la réponse n'est pas bien loin :
2019-05-12T20:17:13+00:00 dad34f22107c {"container_id":"xxx","container_name":"/agents_fluentd_1","source":"stdout","log":"2019-05-12 20:17:13 +0000 [info]: #0 sending 5714975 bytes","app":"agents","service":"fluentd","tag":"agents.fluentd","instance":"joke"}
2019-05-12T20:17:14+00:00 dad34f22107c {"container_name":"/agents_fluentd_1","source":"stdout","log":"2019-05-12 20:17:14 +0000 [warn]: #0 failed to POST http://logs.hostname:3100/api/prom/push (500 Internal Server Error rpc error: code = ResourceExhausted desc = grpc: received message larger than max (5186961 vs. 4194304)","container_id":"xxx","app":"agents","service":"fluentd","tag":"agents.fluentd","instance":"joke"}
Suivi d'une description précise des messages qui n'ont pas pu être émis :
2019-05-12T20:17:14+00:00 xxx {"log":"2019-05-12 20:17:14 +0000 [warn]: #0 {\"streams\":[{\"labels\":\"{app=\\\"video\\\",service=\\\"peertube\\\",tag=\\\"video.peertube\\\",instance=\\\"joke\\\"}\",\"entries\":[{\"ts\":\"2019-05-12T20:17:03.644103Z\",\"line\":\"container_id=\\\"xxx\\\" container_name=\\\"/video_peertube_1\\\" source=\\\"stdout\\\" log=\\\"[video.tedomum.net:443] 2019-05-12 20:17:03.643 \\u001B[32minfo\\u001B[39m: 2a01:: - - [12/May/2019:20:17:03 +0000] \\\"GET /static/webseed/01cd2292-e4e3-4b61-bb74-a4fbdb704f32-360.mp4 HTTP/1.1\\\" 206 16384 \\\"https://video.tedomum.net/videos/embed/01cd2292-e4e3-4b61-bb74-a4fbdb704f32\\\" \\\"Other\\\"\\\"\"},{\"ts\":\"2019-05-12T20:17:03.784652Z\",\"line\":\"container_name=\\\"/video_peertube_1\\\" source=\\\"stdout\\\" log=\\\"\\\" container_id=\\\"xxx\\\"\"},{\"ts\":\"2019-05-12T20:17:03.786381Z\",\"line\":\"log=\\\"[video.tedomum.net:443] 2019-05-12 20:17:03.644 \\u001B[32minfo\\u001B[39m: 2a01:: - - [12/May/2019:20:17:03 +0000] \\\"GET /static/webseed/01cd2292-e4e3-4b61-bb74-a4fbdb704f32-360.mp4 HTTP/1.1\\\" 206 16384 \\\"https://video.tedomum.net/videos/embed/01cd2292-e4e3-4b61-bb74-a4fbdb704f32\\\" \\\"Other\\\"\\\" container_id=\\\"xxx\\\" container_name=\\\"/video_peertube_1\\\" source=\\\"stdout\\\"\"},{\"ts\":\"2019-05-12T20:17:03.786593Z\",\"line\":\"container_id=\\\"xxx\\\" container_name=\\\"/video_peertube_1\\\" source=\\\"stdout\\\" log=\\\"\\\"\"},{\"ts\":\"2019-05-12T20:17:03.786793Z\",\[... suivi de 5Mo de logs non émis]
Fluentd, non content de n'avoir pu émettre un bloc de 5Mo de journaux (qui correspondent à 10s de trafic intense sur PeerTube) comme cette taille dépasse le maximum accepté par Loki, journalise cette erreur en incluant le contenu... des journaux qui n'ont pas été émis. Vous connaissez la suite : Fluentd lui-même est journalisé par Docker, ces quelques 5Mo, gonflés par une batterie d'anti-slash d'échappement, sont rapidement réinjectés dans la boucle, et le tout dépasse à nouveau 5Mo en générant une erreur du même accabit. Effet Larsen.
Comme tout se déroule localement, les choses vont vite. Très vite. Après quelques millisecondes, les journaux internes de Fluentd ressemblent plutôt à :
log":"\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\[... quelques Mo d'anti-slashs]
Au bout d'une seconde environ, Fluentd ne peut plus conserver ces journaux dans ses buffers et s'effondre en bon guerrier.
On trouve rapidement une solution et l'on patch, en limitant la taille des blocs envoyés à Loki d'une part pour ne plus générer cette erreur, mais également en configurant Fluentd pour ne passer par... Fluentd :
- https://forge.tedomum.net/tedomum/documentation/commit/90fff8e5dcd327c1abb46f0610d246e157468b0f
- https://forge.tedomum.net/tedomum/documentation/commit/5ca77708250441d254ad66960db9efe06b473a44
On avait pourtant testé !
Et c'est vrai. Certes pas pendant des mois, mais une petite semaine a vu les journaux de production de pas mal de conteneurs, dont traefik, pointer vers un Fluentd de test afin d'évaluer le bon fonctionnement. Comment se fait-il donc que le défaut n'ait pas été identifié avant un déploiement global ?
C'est que les conditions de tests ont consisté à rediriger spécifiquement chaque conteneur testé vers Fluentd, et jamais Fluentd lui-même. Egalement, les quelques heures de tests en production sur le premier serveur déployé n'ont pas été suffisantes pour déclencher le bug qui dépend grandement du trafic entrant (il est rare en temps normal de générer plus de 1Mo ou 2Mo de journaux toutes les 10 secondes).
Une bonne leçon pour ne pas oublier de tester et de qualifier en conditions au plus près de la production. Avec le recul, ce fut l'un des bugs les moins évidents à investiguer depuis qu'on administre TeDomum.